Skip to content
O. Valadares' Blog
Home
Newsletter
About
Archive
Tags
Tag:
algorithm
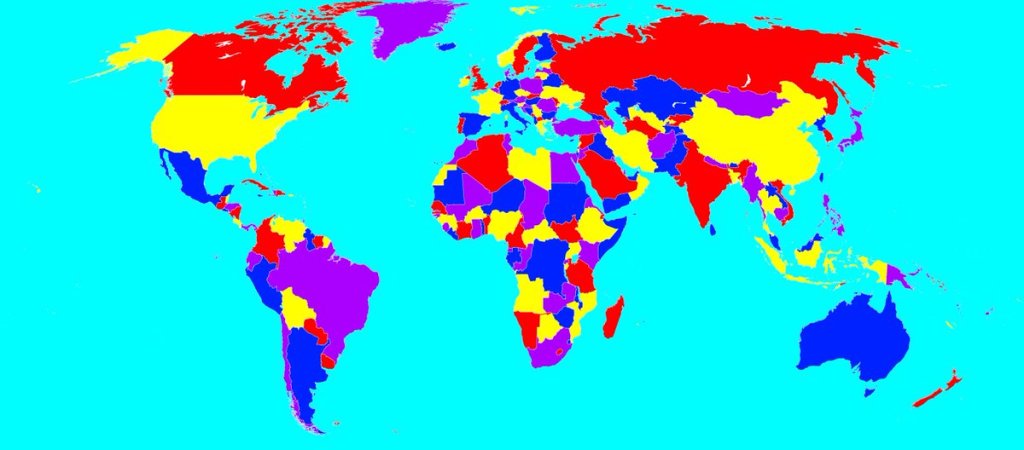
Four color theorem with Prolog
Demystifying Linked Lists / Complete tutorial/implementation with TDD
Understanding the basic of Big O notation
Subscribe
Subscribed
O. Valadares' Blog
Join 25 other subscribers
Sign me up
Already have a WordPress.com account?
Log in now.
O. Valadares' Blog
Subscribe
Subscribed
Sign up
Log in
Report this content
View site in Reader
Manage subscriptions
Collapse this bar