

Big O notation is a famous topic in computer science, but this topic still afraid of a lot of people. Some programmers don’t have a complete cs degree and never studied this, and those who have studied almost always didn’t understand very well.
In this text I will explain what really is Big O, and what you really need to know.
I’ll explain all the basics of Big O notation with examples written in Ruby.
This is not a complete guide of Big O notation if you want to know everything about, at the end of this post I give north of where to continue your study.
Introducing
This text is not recommended for:
- People who have solid knowledge of Big O notation.
- People who want to know advanced topics of Big O
What I’ll explain on this post:
- What is Big O
- The most common notations
- Simple examples
- Simple Benchmarks
First of all, what is Big O notation?
Big O notation is the language and metric we use when talking about growth rates and the efficiency of algorithms. It can be used to describe the behavior of an algorithm in terms of the growth in the number of operations as the number of elements processed increases, with this technique we can evaluate how our code will behave with a lot of data or operations.
If you want a long explanation you can read the big o article on Wikipedia here.
Why is it important? I’ll never use it.
A lot of methods or data structures of every programming language are described using Big O, like binary search that in Ruby can be called Array#bsearch.
First of all, if you always work with small sizes of data and operations, maybe you’ll never use it. But it’s good to understand the basic concepts of algorithms, because it can help you to make better design decisions and construct better algorithms.
Nowadays on the big data century, tons of data and operations are reality. You’ll probably need to design an algorithm thinking on his time or space complexity.
Nowadays on the big data century, tons of data and operations are reality. You’ll probably need to design an algorithm thinking on his time or space complexity.
Tweet
It’s better to know because a lot of methods of your favorite programming language have different times, with Big O you can understand better the performance of each one.
And remember, a lot of big tech companies like Google, Facebook and Amazon asks for big o answers on their interview process, this is very common that is discussed on the legendary book Cracking the Code Interview.
Understanding
Visualizing the complexity
On Big O notation we have a lot of possibilities of notations, and we don’t have a fixed list of runtimes but the most common is:
| Notation | Short Description | Denomination |
|---|---|---|
| O(1) | The best solution possible | Constant |
| O(log n) | Almost good, binary search is the most famous algorith O(log n) | Logarithmic |
| O(N) | When you walk through each data. "ok" solution | Linear |
| O(n log n) | Not bad solution. Most famous algorithm is Merge Sort. | nlogn |
| O(N^2) | Horrible, you can see the example bellow | Quadratic |
| O(2^n) | Horrible, most famous algorithm is quicksort | Exponential |
| O(N!) | The most horrible solution, factorial is when you test each possible solution | Factorial |
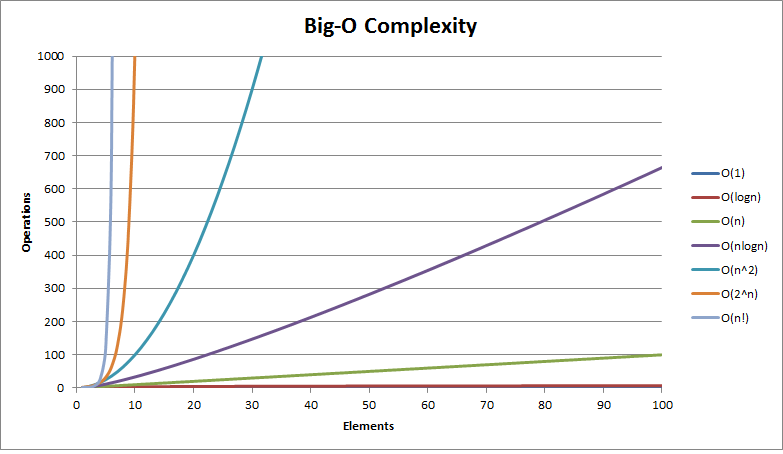
Time or Space?
We can use Big O to describe both time or space, but what it means? Simple, one algorithm that uses O(N) runtime, will use O(N) space too, but it’s not that easy, some algorithms can be O(N) in time complexity but O(N^2) in space.
Time for What?
Data structures or algorithms can have multiple Big O times for multiple actions, for example An Array has O(1) time to access, but O(n) to search (depending on which algorithm you use), all depends on the scope of our code.
Big O, Big Omega, Big Theta?
On this text I’ll not talk about Big Omega and Big Theta because of two reasons:
-
This is a simple guide and I don’t want to dive into deep concepts of computer science.
-
The industry tends to use Big O notation.
Hands On!
Check my last posts:
- Newsletter 76 – 06/2026A curated lists of the best things that I’ve read last month. Issue July 2026.
- Newsletter 75 – 05/2026A curated lists of the best things that I’ve read last month. Issue June 2026.
Presenting our problem
On your life you never thought that some actions of your day spend a lot of time to be done, and you can make simple actions to reduce the time spent? Let’s use a simple example, dictionary(physical edittion, not google), how much time do you need to find a word? Depend of the way you search.
“The Second Edition of the 20-volume Oxford English Dictionary contains full entries for 171,476 words in current use and 47,156 obsolete words. To this may be added around 9,500 derivative words included as subentries.”
This is a lot of data right? Let’s imagine that we’re building an algorithm to search for a word.
Code
For learning purpose on all examples I’ll use an array of numbers not strings.
Let’s create the array that I’ll use on all the next examples. This array will be our dictionary, but instead of words(strings), we’ll use numbers. The word “zoo”, will be the last word of our dictionary and will be represented as number 1000000. As you can see below:
dictionary = []
0.upto(1000000) do |number|
dictionary << number
end
Now, we have an array with one million numbers. Let’s assume that this array of numbers is our dictionary and the 1000000 on the last slot it’s our word “zoo”.
First Solution O(N)
Considering that this dicionary is in alphabetical order, how much time you’ll spend to find the word “zoo” (our 1000000) if you go through each word?
Yes, to find “zoo” you’ll spend a lot of time because you’ll need to go through all the words. These scenarios when we walk through each data, on Big O notation we call O(n), because our algorithm will take N times to find the word, where N is the number of words. Let’s see the code.
Code
Now let’s assume that we’re going though each word until we find the word.
def o_n(dictionary)
dictionary.each do |word|
word if word == 1000000
end
end
o_n(dictionary)
This is a very common and as I described previously, is not a bad solution, but not good to. In terms of difficulty to understand is not hard too, a lot of algorithm O(n) we have iterators on lists.
Second Solution O(1)
Let’s assume that now you already knows what is the location of word zoo on dictionary, every time that you need to search for it you only need to open the dictionary on the page and just read. You don’t need to find for the word, you already knows its location.
Code
O(1) is a algorithm that is idependent of the input size it will always take the same time to execute, the time is constant. The best example of it, it’s access an array:
def o_one(dictionary)
dictionary[1000000]
end
o_one(dictionary)
O(1) is always the best solution, and you probably use it every day, the most commond usage of it is with Hashes.
I think everybody here knows, but Ruby already have Hash implemented.
hash = {
color: "red"
}
hash[:color]
# => "red"
Third Solution O(log n)
Follow my blog to get notified off every new post:
Some people have a lot of difficult to understand the concept of O(log N) algorithm, but I hope that this example with dictionary can help you undersand:
Let’s assume that you don’t know where the word is located, but you know that if you search each word O(N) will spend a lot of time, and you don’t know where the word is located, what will you do? You could start opening the dictionary on a random page and search if the words of this page come before or after the word that you’re looking for if is after you open on another page after this page, and look again… and repeat it until you find the word that you’re searching for.
If you already studied algorithms you probably noted that I described one of the most famous algorithms of all time, the binary search and that is the most famous example of O(log n) algorithm.
Let’s see the code.
Code
For this example, I’ll use a simple binary_search implementation (Not recursive).
def binary_search(dictionary, number)
length = dictionary.length - 1
low = 0
while low <= length
mid = (low + length) / 2
return dictionary[mid] if dictionary[mid] == number
if dictionary[mid] < number
low = mid + 1
else
length = mid - 1
end
end
"Number/Word not found"
end
puts binary_search(dictionary, 1000000)
To identify an algorithm that is O(log n) you can follow two simple steps:
- The choice of the next element on which to perform some action is one of several possibilities, and only one will need to be chosen.
- The elements on which the action is performed are digits of n
You can check more here
Binary search is a perfect exemple of this steps because each time it cut by the half the remaining options.
Like many languages Ruby already have binary search built-in as array methods as Array#bsearch as you can see below:
array = [1,2,3,4,5,6,7,8,9,10]
array.bsearch {|x| x >= 9 }
# => 9
You can read more here
If you think that it’s not enough at you can find better references at the given links, I’ll not explain a lot of maths because it’s a text for beginners.
Fourth Solution O(N^2)
Imagine that you’re searching word by word like on O(N) but for some reason you need to make your search again, this is the O(N^2). This example applied to our history of the dictionary is hard to understand but with code is more easily.
The trick is basically to think that O(N^2) is when we pass through N, N times, so we’ll have N*N that is O(N^2), the most common example is a loop inside a loop.
Code
def o_n2(dictionary)
dictionary.each do |word|
dictionary.each do |word2|
word if word == 1000000
end
end
end
o_n2(dictionary)
Don’t worry, this is a very common case too, almost every person already has done something like that, especially when we’re starting to code that we use the famous quicksort that is a nice example of O(N^2), but this code won’t have a good performance for large data. The best way is think if you can reduce this algorithm to O(log n), some times an O(N^2) can be reduced to O(log n).
Fifth Solution O(n log n)
This is the most hard definition for me, and I admit that I spend hours searching on internet because the definitions that I’ve found didn’t satisfy me (And don’t have much answers on internet).
The simplest explanation that I’ve found is:
O(n log n) is basically you running N times an action that costs O(log n).
O(n log n) is basically you running N times an action that costs O(log n).
Tweet
This is obvious but, makes sense. Let’s examine:
In the binary tree, inserting one node (in a balanced tree) is O(log n) time. Inserting a list of N elements into that tree will be O(n log n) time.
O(n log n) code can be often the result of an otimization of quadratic algorithm. The most famous example of this type is the merge sort algorithm.
For this definition won’t have short history, I definitely didn’t think in anything that makes sense on our history with dictionary.
If you think that this is not enough at references you find links to better understand, I’ll not explain a lot of maths because it’s a text for beginners.
Sixth Solution O(2^N)
Exponencial runtime, this is a very hard definition, like O(n log n). This type of problem is when the number of instructions growth exponentially, it’s common to found it on recursive algorithms, or some search algorithms.
"When you have a recursive function that makes multiple calls, the run time will be O(2^n)"
If you search on internet you’ll probably see a lot of people talking that Fibonacci recursive solution is a good example:
def fibonacci(number)
return number if number <= 1
fibonacci(number - 2) + fibonacci(number - 1)
end
puts fibonacci(10)
For find a O(2^N) you can start following one simple rules:
- O(2^N) denotes an algorithm whose growth doubles with each additon to the input data set. (Exponential growth)
For this definition won’t have short history, too, sorry guys.
Seventh Solution O(N!)
The factorial solution, is very horrible. But I think there’s no example in our history of finding words in dictionary, and I don’t want to dive inside a lot of math in this beginners guide.
O(N!) is every time that you calculate all permutation of a given array of size N.
The most common example of this notation is that solving salesman problem via brute-force(testing every solution possible). (A lot of sites such as wikpedia uses this example).
Code
In Ruby we have a method that returns all permutations of a given array.
array = [1,2,3]
array.permutation(3).to_a
# => [[1, 2, 3], [1, 3, 2], [2, 1, 3], [2, 3, 1], [3, 1, 2], [3, 2, 1]]
This is actually O(N!)
Some Benchmarking
Let’s examine some benchmark of algorithms of each example and compare, for better understanding and understand that Big O really exists.
On this section I’ll use the same implementations of algorithms from previus chapter but using Ruby Benchmarking module to compare the execution times.
4.1 O(1) vs O(N)
For this example we’ll use the same dictionary array created on previus chapter with one million of data.
0.upto(1000000) do |number|
dictionary << number
end
So if we run the algorithms created in th above chapter:
Benchmark.bm { |bench| bench.report("o(1)") { o_one(dictionary) } }
Benchmark.bm { |bench| bench.report("o(n)") { o_n(dictionary) } }
# user system total real
# o(1) 0.000000 0.000000 0.000000 ( 0.000005)
# user system total real
# o(n) 0.060000 0.000000 0.060000 ( 0.052239)
A very low difference, and that’s is why O(N) on the graph of complexity is not very bad, with one million of data he just needed 0.052239s, but and if we growth your dataset to almost 15 million, the O(N) solution will be good? Let’s see:
# user system total real
# o(1) 0.000000 0.000000 0.000000 ( 0.000004)
# user system total real
# o(n) 0.750000 0.000000 0.750000 ( 0.741515)
The time of O(N) solution increased 12.5x more than the array of one million while the O(1) solution stay constant at ~0.000004s, and that’s is very wrong if we’re talking about scalable systems on the big data century.
O(N) vs O(N^2)
First of all, let’s create again an array but this time with lil bit less data:
data = []
0.upto(20000) do |number|
data << number
end
Yes, twenty thousand is good enought to this example, because O(N^2) is very bad, and if you growth you data, you’ll problaby get 100% cpu usage on Ruby process and it will be killed by OS.
Let’s examine the runtime of previus O(N) and O(N^2) algorithms of our dictionary example using benchmark module and the data array created:
Benchmark.bm { |bench| bench.report("o(n)") { o_n(data) } }
Benchmark.bm { |bench| bench.report("o(n^2)") { o_n2(data) } }
# user system total real
# o(n) 0.010000 0.000000 0.010000 ( 0.000963)
# user system total real
# o(n^2) 19.550000 0.000000 19.550000 ( 19.560149)
Obviusly that this number will vary
This difference is pretty high, and that is where Big O came. Remember, on Big O we’re talking about the "behavior of an algorithm in terms of the growth in the number of operations as the number of elements" as I talked on previus chapter.
Ok, twenty thousand of data is pretty high from some people, and if we try an array of five thousand, is it enought?
user system total real
o(n) 0.000000 0.000000 0.000000 ( 0.000252)
user system total real
o(n^2) 1.330000 0.000000 1.330000 ( 1.329480)
If you’re thinking: “The difference is so much smaller, I don’t need to optimize this code.”
You’re pretty wrong depending of your situation, because if we get the difference between an execution of each algorithm we have 1.329228s of difference, and it can be an eternity for your costumer if you consider that your client wait for 1.329228s three times each day, we’re stealing 27.9s per week of your costumer, and we’re only working with five thousands of data, I’m sure that a lot of people work with a lot of more.
So, in this case of an O(n^2) I pretty recomend that you try to reduce this for an O(n log n)
O(N!)
This is a nice test because if we use one million of numbers the algorithm will take more than 10 hours to execute on my machine, and if I use five thousand of data (like on the previous example) it will take a nice time too, so to show the O(N!) in action I’ll need to use only 500 numbers.
On this example I’ll use the Array#permutation, method of Ruby.
dictionary = []
0.upto(500) do |number|
dictionary << number
end
Benchmark.bm { |bench| bench.report("o(!n)") { dictionary.permutation(3).to_a } }
And the final output is weird:
# user system total real
# o(!n) 25.530000 1.650000 27.180000 ( 28.155015)
28.1s with 500 numbers.
Finishing
I’ll not benchmark all algorithms and data structures, but I pretty recommend that you study and test others one. Specially the O(log n)
What’s Next?
If you want to be a rockstar at *Big O* just keep studying, reading a lot.
You can read:
This last books, have one chapter 100% dedicated to Big O notation, and I pretty recommend for those who wants to study more deep.
You can fallow the reference links bellow and study by yourself.
Final thoughts
It was a very long post, and I know it, but I think that a good understand of the big o principles is important for a lot of software engineers, to the daily work or for coding interviews.
If you have any question that I can help you, please ask! Send an email (otaviopvaladares@gmail.com), pm me on my Twitter or comment on this post!
Reference
- How to benchmark ruby
- Whats does O(log n) means
- Good docs from one university
- How to calculate Big O
- Linear time vs Quadratic Time
- How to calculate complexity of recursive functions
- O(log n), why is that name?
- Little bit more about O(log n)
- And more about O(log n)
- Time complexity wikpedia
- Good video about
